1. Real Time System
a) Hard real time system
> 어떤 task가 주어진 시간안에 반드시 완료되어야 함
> 자동차 에어백, 자율주행 등등
b) Sort real time system
> 데드라인이 중요하긴 하나 못맞춰도 기능적 문제는 없음
> 실시간 스트리밍, 온라인게임같은거
> RealTime CPU scheduling은?
> Preemption이 가능한 우선순위 기반으로 스케쥴링함
> 왜냐면 non-preemptive 알고리즘을 채용하게 되면 데드라인을 만족하기 어렵기 때문
+ Real Time에서는 Task(Process)가 주기적임을 가정함
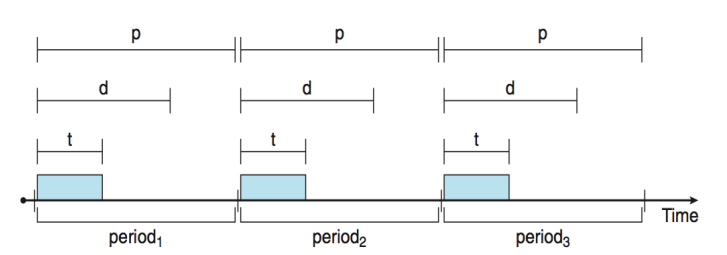
t는 한번 수행시 t만큼의 시간이 걸리는 것
d는 데드라인
p는 주기
2. RMS
- Rate Monotonic Scheduling
> periodic한 Task에게 Static한 우선순위를 할당하는것
> 한번 할당시 절대 우선순위는 변하지 않음
> 이 process의 데드라인이 다음 arrival time과 일치한다고 가정
> RMS에서는 period가 짧을 수록 높은 우선순위를 줌
> 즉 CPU resource를 자주 요청하는 Task에게 높은 우선순위 부여 ( rate = 1/p가 클수록 우선순위 높음)
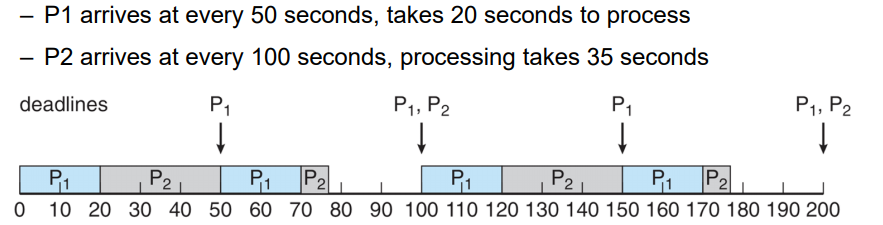
P1의 rate는 1/50, P2의 rate는 1/100 따라서 P1의 우선순위가 더 높음
1. P1, P2가 0에 arrival 한 상태임
2. 우선순위가 높은 P1이 20초만큼 실행됨
2. P1의 작업이 끝나고 P2가 실행됨
3. P2가 실행되는 도중 50초일때, 다음 P1의 arrival time이 시작됨
4. 따라서 preemption이 일어나서 P1에게 CPU할당이 넘어감
5. 이후 반복적으로 실행
> RMS는 Static priority를 사용하는 알고리즘으로, 가장 optimal한 알고리즘임
> 즉, RMS로 스케쥴링 할 수 없는 Static 알고리즘이면 어떤걸로도 할 수 없음
>>이걸 계산할 수 있는 공식이 있는데, N은 프로세스 개수
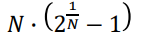
CPU Utilization U의 합이 위의 공식 값보다 크게 나오는경우 어떤 방법을 써도 스케쥴링이 불가함
위의 예제로 보면
U = 20/50 + 35/100 = 0.75 = 75%의 수치를 가짐
공식에 2를 대입하면 약 83%정도가 나옴. 따라서 공식의 값이 더 크므로 이 알고리즘은 RMS로 수행 가능함
3. EDF
> 각 Task의 우선순위를 데드라인에 가까울수록 높여줌
> RMS보다 좋은 성능을 지님.
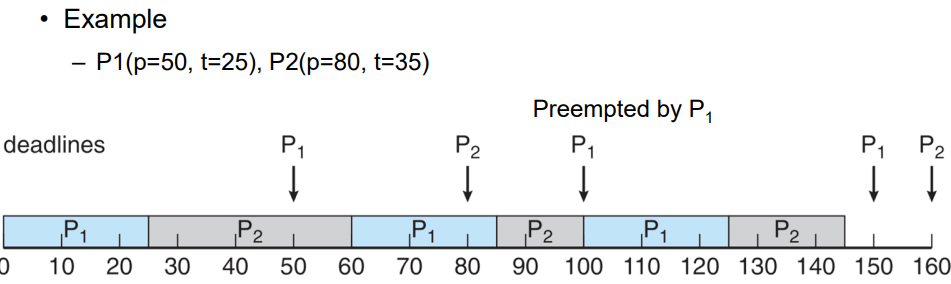
1. P1,P2가 0때 arrival됨
2. P1의 데드라인이 50이므로 더 데드라인에 가깝기 때문에 P1에 우선순위 부여
3. P1이 정해진 25만큼 수행됨 이후 P2가 진행됨
4. 50때 P1이 arrival됨 하지만 P2의 데드라인이 더 가깝기 때문에 Preemption되지 않음 P2는 35만큼 계속 진행됨
5. 반복
EDF 알고리즘도 공식이 있다.
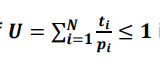
CPU Utilization이 1보다 작거나 같아야만 EDF 알고리즘을 수행할 수 있음
4. Issues in Process Scheduling
> 멀티 프로세서 스케쥴링에서는 여러 프로세스와 코어들이 동일한 하드웨어 성능을 지닌다고 가정함
> 아래처럼 두가지 경우로 나뉨
a) Asymmetric Multiprocessing
> 대장이 있어서 대장이 지시를 내림
b) Symmetric Multiprocessing
> 대장은 없고 각자가 각자의 일을 함
5. Processor Affinity
>멀티 프로세스 스케쥴링 시 프로세스 Affinity를 고려해야 함
a) Soft Affinity
> Best effort로 노력은 함 하지만, 보장해주진 않음
b) Hard Affinity
> 어떤 CPU에서 돌건지 명시를 해 줘야 함
이게 왜 필요하냐면, CPU 1에서 돌던 프로세스 P1이 Ready Queue에 들어가게 되면 CPU1에는 P1의 정보를 캐시로 가지고 있단말이지. 그런데 P1이 Ready queue에서 나올 때 CPU 2로 넘어가면 CPU2에는 P1의 정보를 가지고 있지 않거든. 이때, CPU1의 캐시를 복사해오는 방법이 있고, 메모리에서 다시 데이터를 가져와서 캐시를 채우는 방법이 존재 해
5. Load Balancing
> 멀티 프로세서에서 고려해야 할 점
a) Push migration
> 로드가 많은 CPU에서 적은 CPU로 넘겨줌
b) pull migration
> 로드가 적은 CPU에서 많은 CPU껄 가져옴
6. Multicore Processors
> 코어들은 공유할수있는 캐시를 가지고 있음
> 이런 멀티코어 아키텍쳐의 이점을 잘 활용하기 위해서는 스케쥴러가 코어 organization을 잘 이용해야함
> 예를들어 CPU가 어떤 메모리에 있는 데이터에 접근하려 할때, 이용 가능한 상태가 될 떄 까지 꽤 많은 시간이 걸림
> 왜냐하면 CPU가 메모리보다 속도가 월등히 빠르기 때문 이런 CPU가 메모리를 기다리는 상황을 Memory stall이라고 함 이 상태가 일어나는동안 CPU는 IDLE상태로 기다리게 됨 >> 즉 낭비임 > 그래서 하이퍼스레딩 등의 방법으로 해결함
7. Scheduler
a) short term scheduler
> 우리가 지금까지 말하던 CPU스케쥴러 >> 레디 큐에있는 여러 프로세스 중에 다음번에 CPU사용하게 될 프로세스 선택하는 것
> ms단위로 굉장히 빈번히 호출됨 그래서 기본적으로 빨라야 해, 또 Context switching의 오버헤드가 낮아야 함
b) long term scheduler
> job scheduler라고도 함.
> 기본적으로 하드디스크에 있는 프로그램을 메모리에 로드해서, 프로세스를 만듦. 그리고 해당 프로세스를 레디큐에 집어넣으면서 레디상태로 만듦
> 하드디스크에 있는 프로그램을 메모리에 로드해서 프로세스로 만들어서 레디큐에 넣는 역할을 하는게 job scheduler
> 멀티프로그래밍의 정도를 결정하는 역할을 함
> short term에 비해 덜 빈번하게 발생함, 수초에서 수분단위로 발생
> 얘는 I/O, CPU bound 가 잘 혼합될수 있도록 잡을 선택할 수 있어야함
> 한쪽에만 치우치면 다른쪽의 utilization이 낮아짐
c) medium-term scheduler
> 기본적으로 메모리 할당을 담당함
> 어떤 CPU에서 프로세스가 돌고 있다가 I/O opereation 처리하기 위해 I/O 큐에 들어가서 Sleep으로 대기하게 됨
> 이 경우 해당 프로세스는 메모리 상에 프로세스 관련된 데이터가 있는데, 이걸 굳이 메모리에 남겨둘 필요 없어서 하드디스크같은데다가 저장을한 뒤, 그 공간을 다른 프로세스에 사용함 >> 이런걸 Swap OUT이라고 함
> 해당 프로세스가 I/O작업을 끝내고 다시 Wake up하게 되면 하드에 저장되어있던 관련 데이터도 다시 메모리로 올라감 >> 이 경우를 SWAP IN 이라고 해
> swap out, in을 합쳐서 swapping이라고 해
> 멀티프로그래밍의 정도를 줄이는 역할 > active 상태의 프로세스를 줄이는 역할
> 반대로 longterm는 멀티프로그래밍의 정도를 늘리는 역할
정리하자면 Longterm은 디스크에 있는 프로그램을 메모리로 로드해서 프로세스로 만든 뒤, 레디 큐로 넣어주는 역할
Short term은 ready queue에 있는 프로그램을 하나 선택해서 CPU를 할당할 수 있도록 dispatch해주는 역할
Midterm은 I/O oepration을 위해 waiting하는 프로세스를 메모리에서 제거하고 디스크에 저장, 다시 레디상태로 될때 디스크에있던 정보들을 다시 메모리에 로드함 >> 스와핑
8. algorithm Evaluation
a) Deterministic evaluation
>이론적인 방법 중 하나, 미리 정해져 있는 특정 워크로드에 대해 해당 알고리즘의 퍼포먼스를 계산하는 방법
정확도가 굉장히 떨어짐
b) Queueing Model
> 레디큐에 프로세스들이 대기하다가 OS가 하나를 꺼내서 CPU할당해줌
> 이런 양상을 확률적 모델로 모델링하는것이 큐잉 모델
> 프로세스가 도착하는 패턴이나, CPU사용 시간, I/O버스트 타임을 확률적 모델에 기반해서 모델링 함
> 큐잉 모델을 통해 여러 스케쥴링 알고리즘들을 평가 할 수 있음
c) Simulation
> 기본적으로 컴퓨터 시스템에서 프로그램을 통해 만든 모델
> 프로그램을 통해 스케쥴링 시뮬레이션을 돌릴 수 있음
> 시뮬레이션을 돌리기 위해서는 워크로드를 수집해야함. 여러 태스크의 정보를 수집해야하는데
> 정보 수집시에도 두가지 방법이 있는데
i) 태스크에 대한 실행시간, 주기 같은 특징에 대한 값들을 random하게 생성할 수 있음
ii) 실제 컴퓨터 시스템에서 데이터를 수집해서 거기에 맞게 정확한 태스크들을 생성
d) implementation
>가장 정확하지만 가장 무식한 방법
> 직접 구현해보고 시스템에 넣어보는것
'학교 수업 > 운영체제' 카테고리의 다른 글
| 운영체제 || 9. Process Scheduling II (0) | 2021.04.17 |
|---|---|
| 운영체제 7 || thread (2 (0) | 2021.04.17 |
| 운영체제 6 || 스레드(threads) (0) | 2021.04.17 |
| 운영체제 || 5. Inter Process Communication (0) | 2021.03.29 |
| 운영체제 || 4. Process (0) | 2021.03.19 |



댓글