네트워크 레이어에서 하는 일을 먼저 복습하자.
크게 두 가지가 있었어, 포워딩과 라우팅이야.
포워딩은 인풋으로 들어온 패킷을 아웃풋으로 내보내는 것이고 Data Plane이고,
라우팅은 포워딩 테이블을 만드는 활동이야. Control Plane에 속해
Control Plane, 라우팅에 대해 간략하게 배워 볼거야.
제어 평면에는 두가지 방법이 존재 해.
하나는 목적지를 기반으로 하는 전통적인 방법이고, 다른 하나는 SDN이라고 해서
중앙에 라우팅을 해 주는 서버를 두고, 그 서버에서 테이블을 배정받는 방식이야.
자세한건 뒤에서 배우고, 지금은 간략하게 알아만 놓자.
자, 그러면 라우팅이라는 것은, 어떻게 길을 잘 설정해서 갈건가에 대한 부분이지?
그러면 어떤 알고리즘을 사용할까?
이것도 크게 두가지가 있어,
Link state라고 해서 어떤 링크의 상태를 기반으로 한 알고리즘
Distance vector라고 해서 목적지까지 가는 짧은 거리만을 가지고 가는 알고리즘이야
Link state에서 가장 중요한 특징은, 모든 라우터가 전체 네트워크 안에 다른 어떤 라우터들이 존재하고, 거기 까지 가는 비용은 얼마고 하는 정보를 다 알고있어야 해.
다시 말해서 모든 라우터가 정확하게 같은 정보를 모두 가지는거야.
Distance vector는 각각의 라우터는 전체에 대한 그림을 가지고 있지는 않아, 하지만 물리적으로 연결되어 있는 인접한 이웃의 정보만 알고 있고, 그냥 가깝게 갈 수 있는 이웃한테 넘기는거야.
전체에 대한 정보는 필요 없고, 내 이웃한테만 넘기면 되는거지.
Link State먼저 살펴보자.
Link State는 Dijkstra's algorithm이야. 흔히 말하는 다익스트라 알고리즘이지.

자세한 알고리즘의 작동 방식은 자료구조를 공부하면서 배울 거니까, 자세한 설명은 넘어가도록 할게.
간단히 말하면 위의 표처럼 작동이 되는건데, u에서부터 시작한다고 치면, u에서 있는 짧은 거리로 넘어가고, 넘어 간 곳에서 또 짧은 거리로 이동하고 하는 방식이야.

중요한점은 위의 각 라우터들이 다익스트라 알고리즘을 끝내고 나면 위의 그림과 같은 테이블을 모두 같이 가지고 있는거야. 네트워크의 크기가 커지면 커질수록 정보의 양이 당연히 많아지겠지?
Dintance Vector
반면, Bellman Ford 알고리즘을 사용하는
Dintance Vector는 네트워크 전체에 대한 정보를 가지고 있지 않아,
대신에 자기의 근접한 이웃에 대한 정보만 가지고 있는거지.
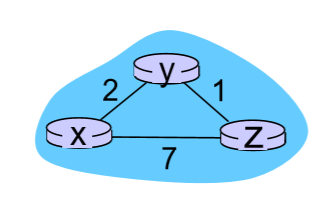
이렇게 x,y,z 세 개가 연결되어 있다고 치면,
x,y,z는 각각 자신이 연결되어 있는 이웃과, 그 코스트를 저장 해 두는 테이블을 먼저 만들어,
x는 y까지2, Z까지 7 이런식으로.
그리고 나서는, X의 표를 Y와 교환하고, Z와 교환을 해.
당연히 Y,Z도 각 이웃에 대한 표를 교환을 할거야.
그러면 Y는 Z까지 가는 길이 1이라고 알려줄거고,
X는 Z로 바로 가는 7보다
Y를 통해가면 3이라는걸 알 수 있으니까, Y를 통해서 보낸다는거지.

전체적인 표는 이렇게 생겼어. 숫자 따라서 가 보면 어떻게 작동하는지 쉽게 보일거야.
중요한점은 안정화가 될 때까지, 테이블을 주고 받고 하는거야.
Link State와 Distance Vector의 장단점이 뭘까?
먼저 만들어지는 메세지의 양을 따져보자.
Link State는 n개의 라우터가 있고, E개의 링크가 있으면, 총 만들어지는 메세지는 O(N*E)가 될거야
많아지면 많아질수록 그만큼 주고받는 메세지도 많아지는거지,
하지만 DV의 경우는 이웃들간의 교환만 가능하니까, 메세지의 양은 좀 적어.
또, 안정화 시간에 대해서 따져볼까?
LS의 경우에는 딱 일정한 시간 O(NE)개의 메세지를 통한 O(N^2)의 알고리즘이란 말이지.
DV의 경우에는 이웃들만 교환을 하니까 메세지의 개수 측면에서는 이득을 볼 수 있어
하지만, 최악의 경우에는 안정화까지의 시간이 오래 걸리고, 무한으로 패킷이 회전하는
Count to infinity 문제가 생길 수 있어, 이 경우에는 안정화 시간이 엄청 오래 걸리는거지
마지막으로 오류가 생겼을때는 어떻게 될까?
한 라우터가 잘못된 링크 코스트를 뿌릴 때,
LS의 경우 각 라우터가 자기 테이블을 계산하기 때문에, 자기만 오류가 생겨
하지만 DV의 경우는 잘못된 코스트를 이웃한테 전달하면,
그 이웃이 또 잘못된 코스트를 또 이웃한테 전달할거란 말이야.
에러가 계속해서 전파되어 나가는거지, 코로나처럼
결국에 LS와 DV 둘 다 어느게 우위에 있다고 말하기가 힘들어, 각각의 장단점들이 존재하고,
장점보다 단점이 더 적은 상황에서 적절하게 쓰이는 거지.
실제로도 두 알고리즘 모두 인터넷에서 혼재해서 사용하고 있어.
'학교 수업 > 컴퓨터 네트워크' 카테고리의 다른 글
| 5장, Network layer :: AS 내부의 라우팅/ intra AS routing / OSPF (0) | 2020.06.21 |
|---|---|
| Network layer :: 3-4. IPv6 (0) | 2020.06.18 |
| Network layer :: 3-3. NAT(Network address translation) (0) | 2020.06.17 |
| Network layer :: 3-2. IP address, IPv4, fragment (0) | 2020.06.17 |
| Network layer :: 3-1. IP addressing, CIDR, DHCP (0) | 2020.06.17 |




댓글