우리는 지금껏 Cost Function이 최소가 되는 theta를 찾으려고, Gradient descent를 사용하여 적당한 Theta를 Iteration으로 찾아내었다.
오늘 알아볼 Noraml equation은 경사 하강법을 사용하지 않고, 한번의 연산으로 Theta를 찾아내는 방법이다.
어떻게 이게 가능할까?
오늘 알아볼 Normal equation을 통해 가능하다.
[Normal Equation]
먼저 Feature가 하나인 경우를 살펴보자.
Cost function은 2차방정식의 형태가 될 것이다. ( 가설함수가 1차이기 때문)
따라서 그냥 손으로, J(theta)의 값의 미분한 결과가 0이 되도록 풀면 풀린다.
여러개의 Feature를 사용해도 똑같은 방식으로 풀 수 있다.
feature가 여러개인 경우는 그냥 단순하게, 각 파라미터에 대해 편미분을 통해 풀 수 있다.
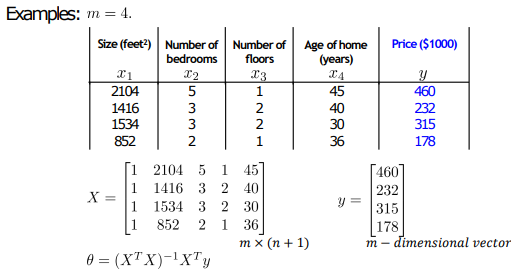
예시를 살펴보자, 먼저 X행렬에 X0인 1을 전부 추가해준다.
이후, y = X*θ이기 때문에, 역행렬을 곱해서 θ를 구할 수 있게 된다.
X는 정방행렬이 아니기 때문에 X의 전치행렬을 먼저 양변에 곱한다.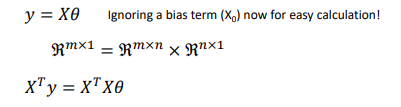
이후 X와 X의 전치행렬의 곱의 역행렬을 양변에 곱해준다.
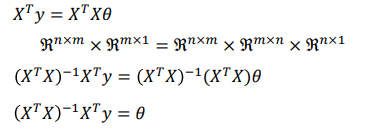
행렬의 차원을 잘 살펴보도록 하자.
위와 같은 식을 통해 theta를 한번의 연산으로 구할 수 있다.
이렇게 그냥 역행렬을 해 버리면 될텐데 왜 이 방법을 사용하지 않을까?
시간적인 비용 때문이다.
역행렬을 구하고, 곱하는 과정이 생각보다 오래걸린다.

위는 Gradient descent와 Normal Equation의 차이점을 보여준다.
Training data의 개수인 m이 많은 경우에 Gradient descent는 이터레이션을 해야하므로 성능에 영향을 미친다.
하지만 Normal Equation인 경우, m이 매우 커도 별 상관이 없다. 어차피 n*n 행렬이 만들어지기 때문이다. (물론 X의 Transpose를 구할때는 영향이 조금 있을것이다.)
하지만 Feature의 개수인 n이 많아지면 조금 문제가 생긴다.
Feature의 개수가 10000만 넘어가도 계산하는데 엄청 오래 걸린다고 한다.
'학교 수업 > 기계학습' 카테고리의 다른 글
| 3. Linear Regression multiple variable (2) - gradient descent (0) | 2021.10.17 |
|---|---|
| 2. Linear Regression with multiple variable (1) (0) | 2021.10.17 |
| 1. 선형 회귀 ( Linear Regression) (0) | 2021.09.08 |



댓글